Business Checks
Business Check reimagines fragmented Excel workflows as a SQL-powered, hybrid UI that balances flexibility with governance. The solution streamlines processes, establishes transparency, and creates an audit-ready system that teams can trust. I led the initiative from concept to roadmap-ready spec—defining the product vision, aligning cross-functional stakeholders, and designing the core workflows. Acting as the bridge between design, product, and engineering, I ensured the solution was scalable, intuitive, and grounded in real-world team needs.
Snapshot
| Role | Senior Product Designer, acting as project lead (sole designer) |
|---|---|
| Leadership | Set vision and trade-off strategy; facilitated Eng, QA, PM, and PPS alignment; mentored two junior designers on data-ops concepts |
| Problem | 40 + client-specific Excel “business-check” scripts caused silent data errors, manual fixes, and zero client visibility: undercutting the org’s push toward self-serve analytics |
| Mandate | Demonstrate how to bring the checks on-platform using the current team and the existing SQL engine: no extra headcount and no deep back-end rework. |
| Status | The design package is ~80% drafted; the remaining specifications are pending and will be finalized when development resumes on the 2025 roadmap. |
| Impact to date |
Four teams behind a single hybrid UI ↔ SQL approach
direct Design↔PPS channel (first time) roadmap-ready epics and reusable patterns now parked in the design system |
1. Business & Stakes
The work began as a narrow request: “Can we drop a SQL-builder UI into the product? However, discovery revealed a larger issue: hundreds of off-platform scripts were causing silent data errors and consuming support resources. I reframed the effort into a Centralized Business Check Repository that would surface, govern, and track every check, transforming a tooling request into a self-serve data-quality initiative.

2. Problems & Goals
| Pain-point (❌) | Target outcome (✅) |
|---|---|
| 40 + client-specific spreadsheets → hard to version, audit, or even find the latest copy | Central instance governed by PPS that publishes vetted checks to every client instance: clients see and run the checks in their environments |
| Zero transparency: neither PPS nor clients see check results until dashboards break | In-product tracking and audit trail: capture pass/fail events, surface trend charts, and establish a baseline data-quality metric for future optimization |
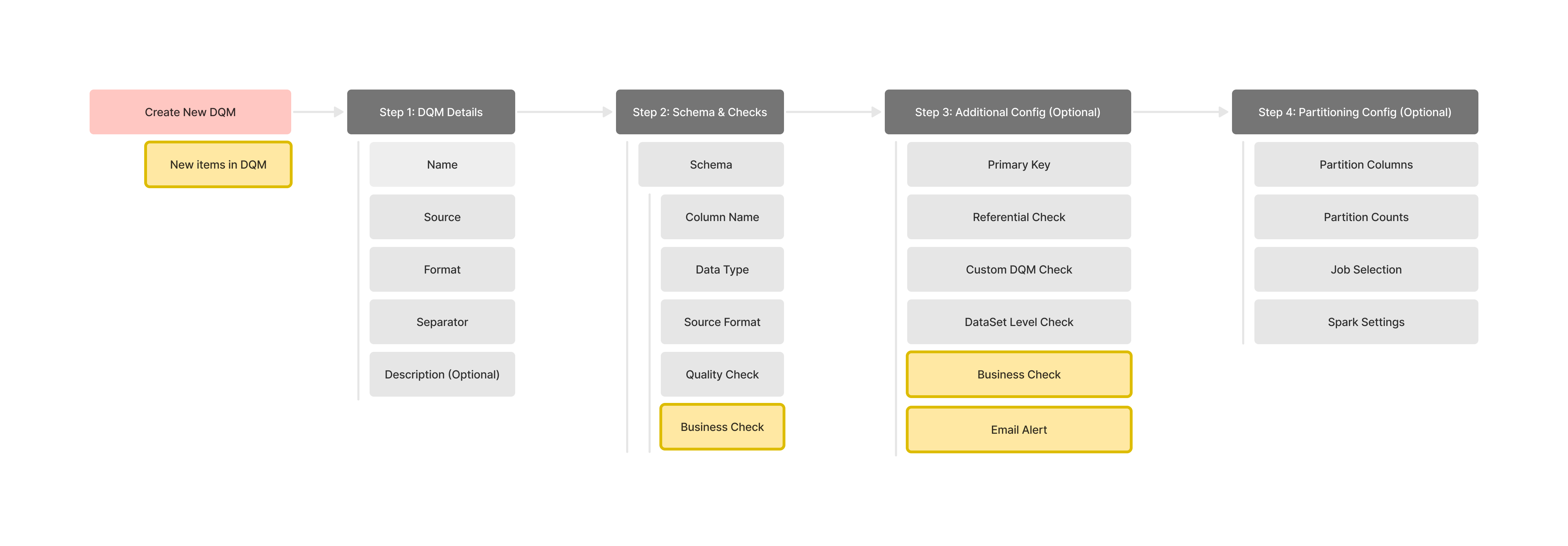
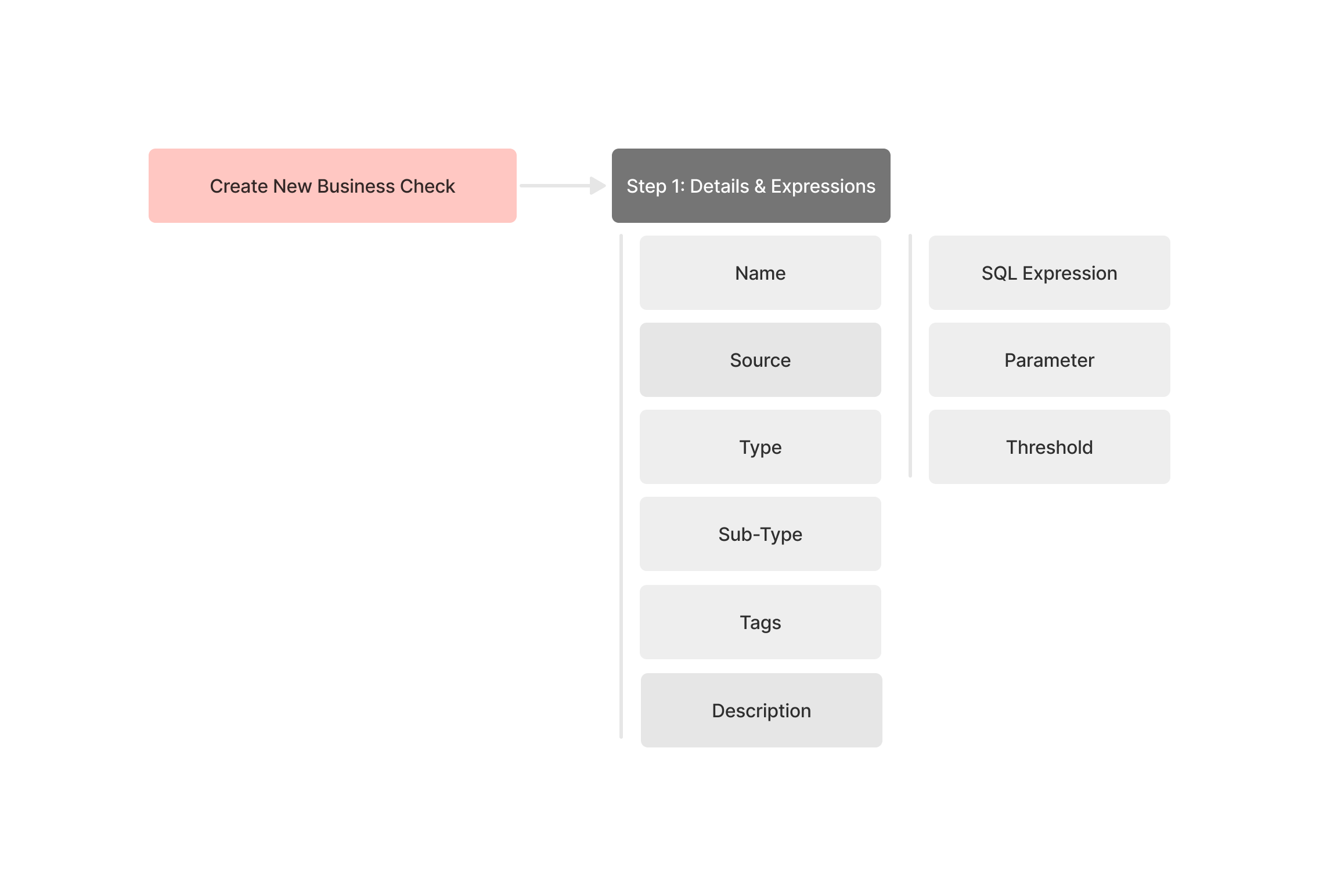
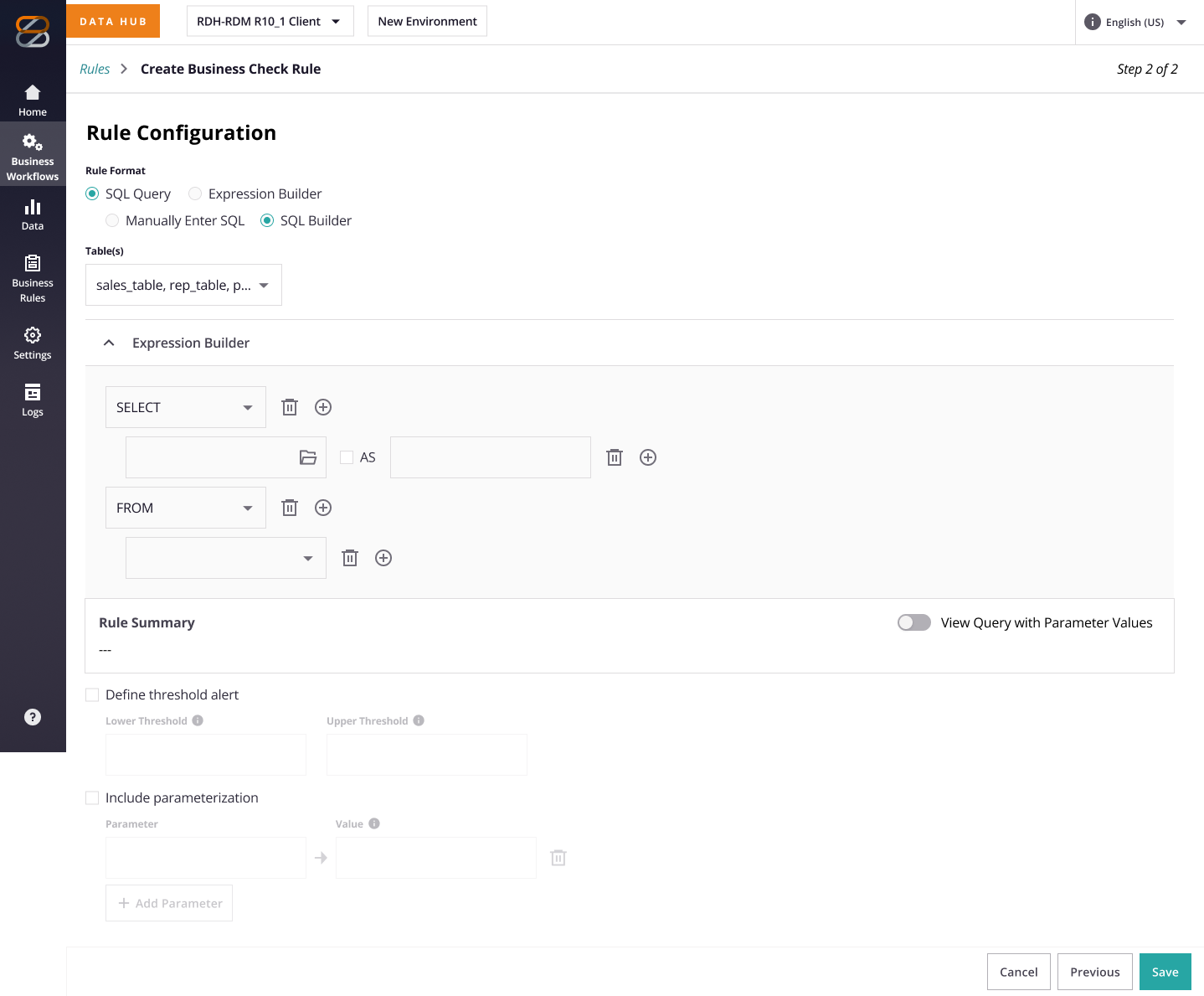
| Writing or fixing a check requires SQL fluency | Enable non-technical users to create and edit checks without SQL expertise. |
With the rough goal in mind, I began to brainstorm to understand where this new feature fits in the existing IA with consideration to the hierarchy of data op process and the existing structure of the IA layout. As well as sketching out a rough process and wireframes to socialize it with stakeholder teams.
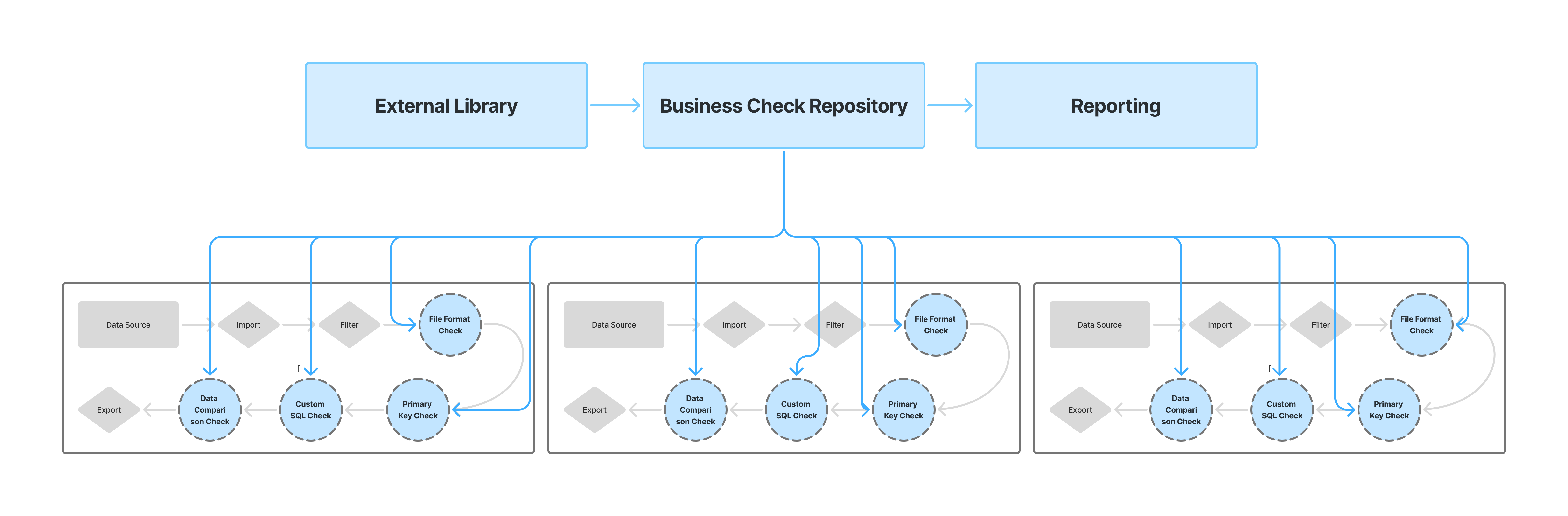
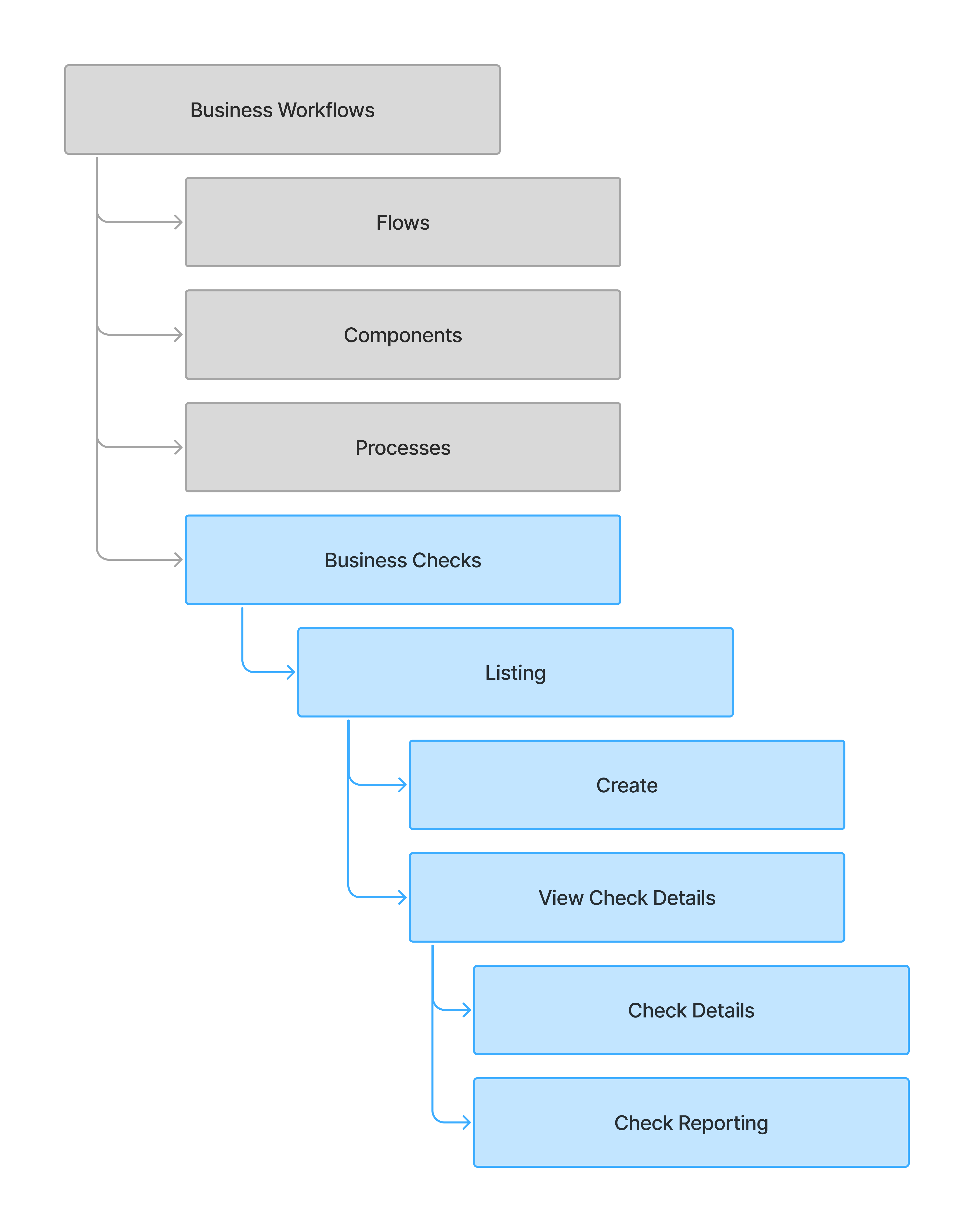
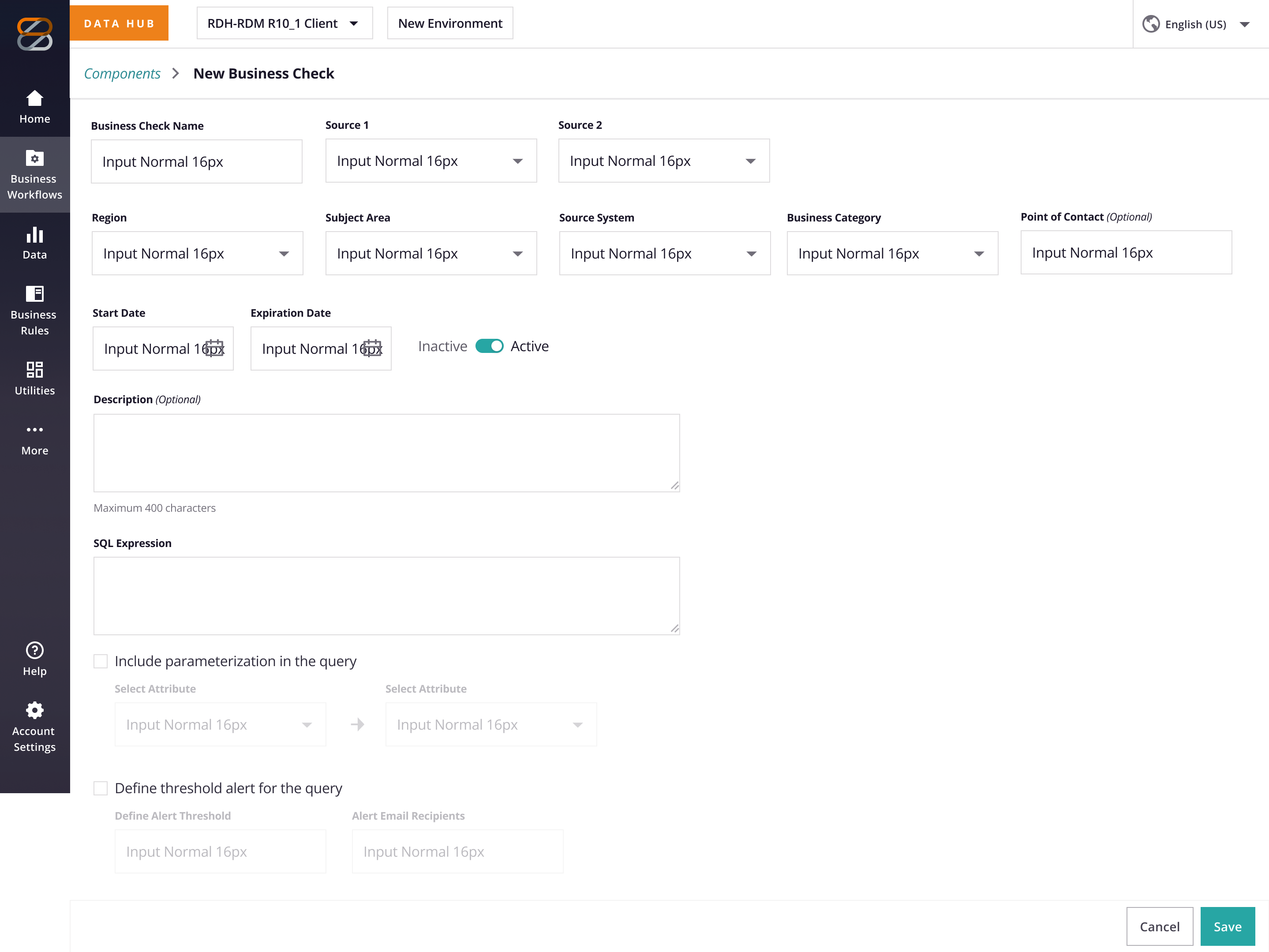
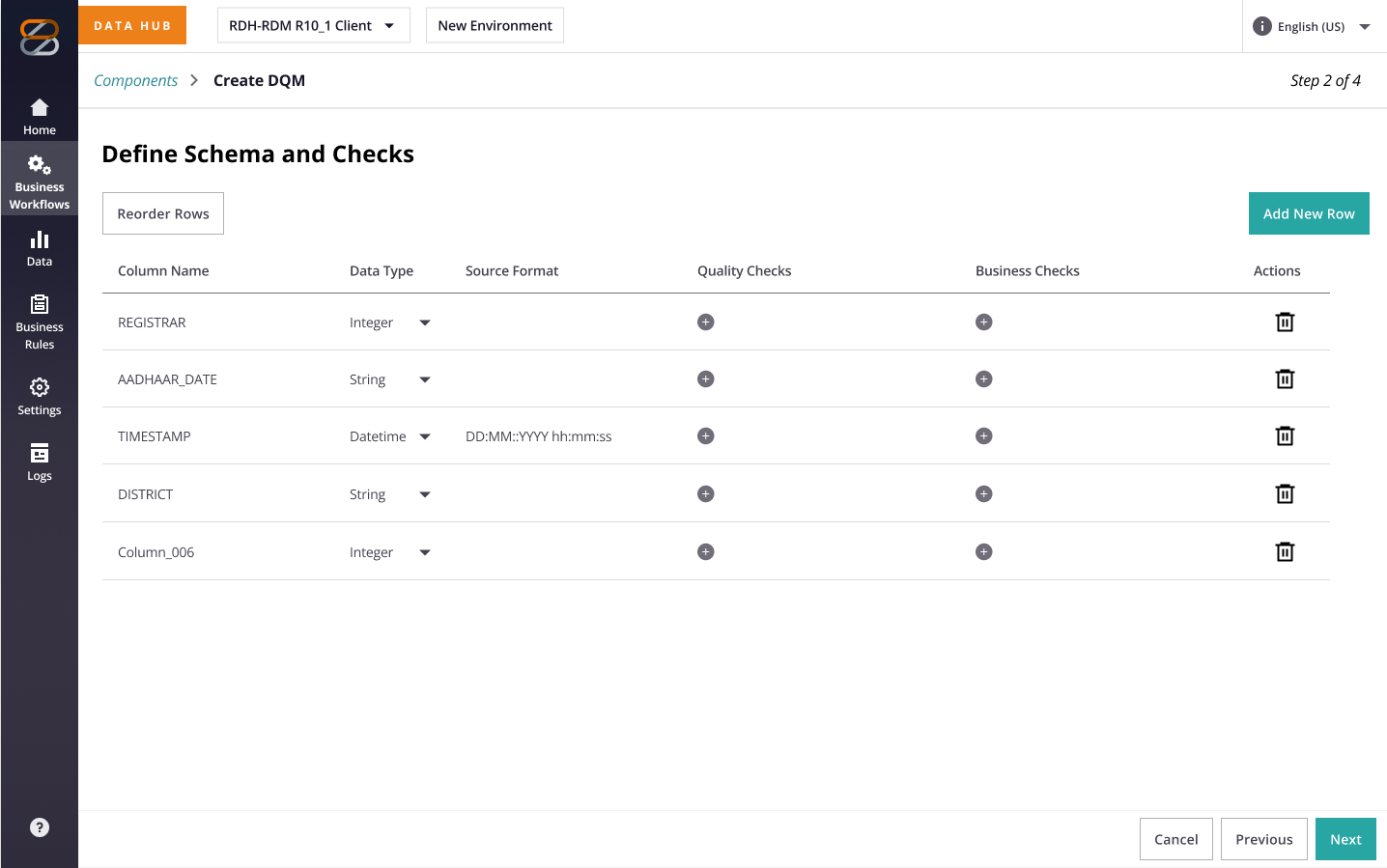
3. Strategy & Process
3.1. Discovery & Alignment
- Joined a deep-dive call with the PM to frame why / for whom / what.
- Walked through legacy spreadsheets with PPS analyst to map where checks run (offline → ingest → transform).
- Set up weekly syncs with Architecture, Engineering, and QA to vet technical feasibility and keep everyone informed about the latest design updates.
3.2 Concept & Trade-offs
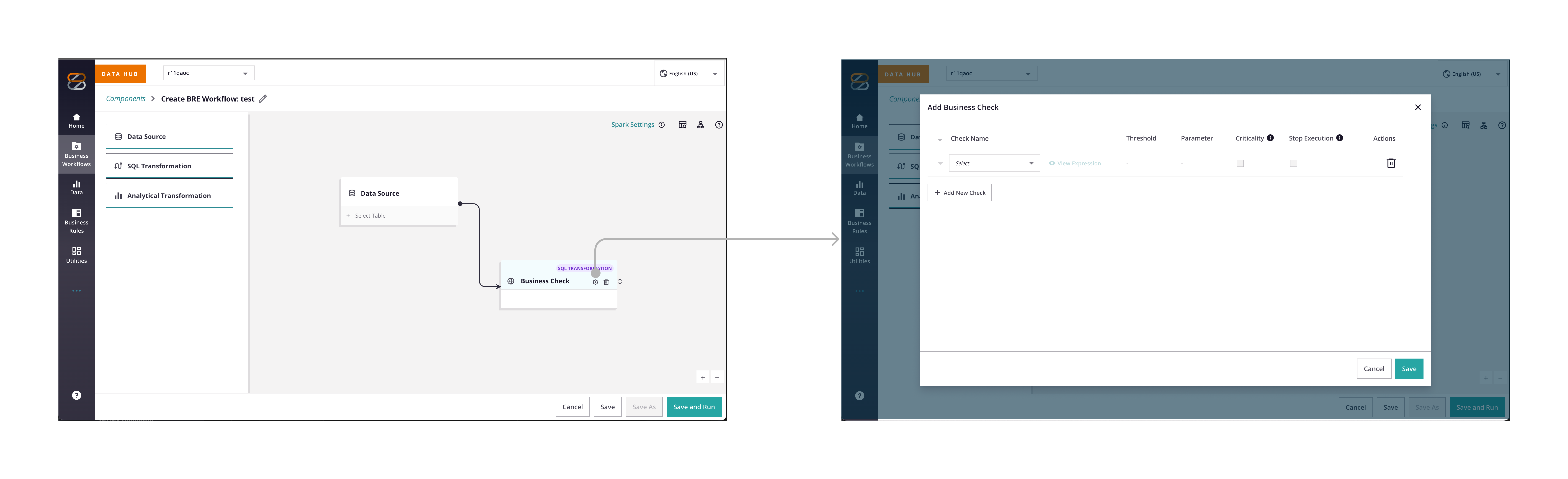
The key part is how we can help users create checks when they are not proficient in SQL? Together, we explored a couple of options to understand the pros and cons.
| Options | Kept? | Rationale |
|---|---|---|
| SQL-only UI editor | ❌ | Does not address the needs of non-technical users. This also raises security concerns, as users can utilize transformative SQL statements to modify source data. |
| Drag-and-drop builder | ❌ | Despite a high development effort, it still doesn’t address the needs of non-technical users. |
| Templated Check Builder | ❌ | High lift; requires analyzing the SQL structure of all existing checks to identify common patterns that can be templatized. |
| Hybrid toggle (Simple Checks Template + SQL) | ✅ | Balances ease + power; medium effort |
We ultimately chose the hybrid approach; not the most intuitive option for every user, but the one that struck the right balance between usability, coverage of key use cases, and what was feasible within our time and engineering constraints.
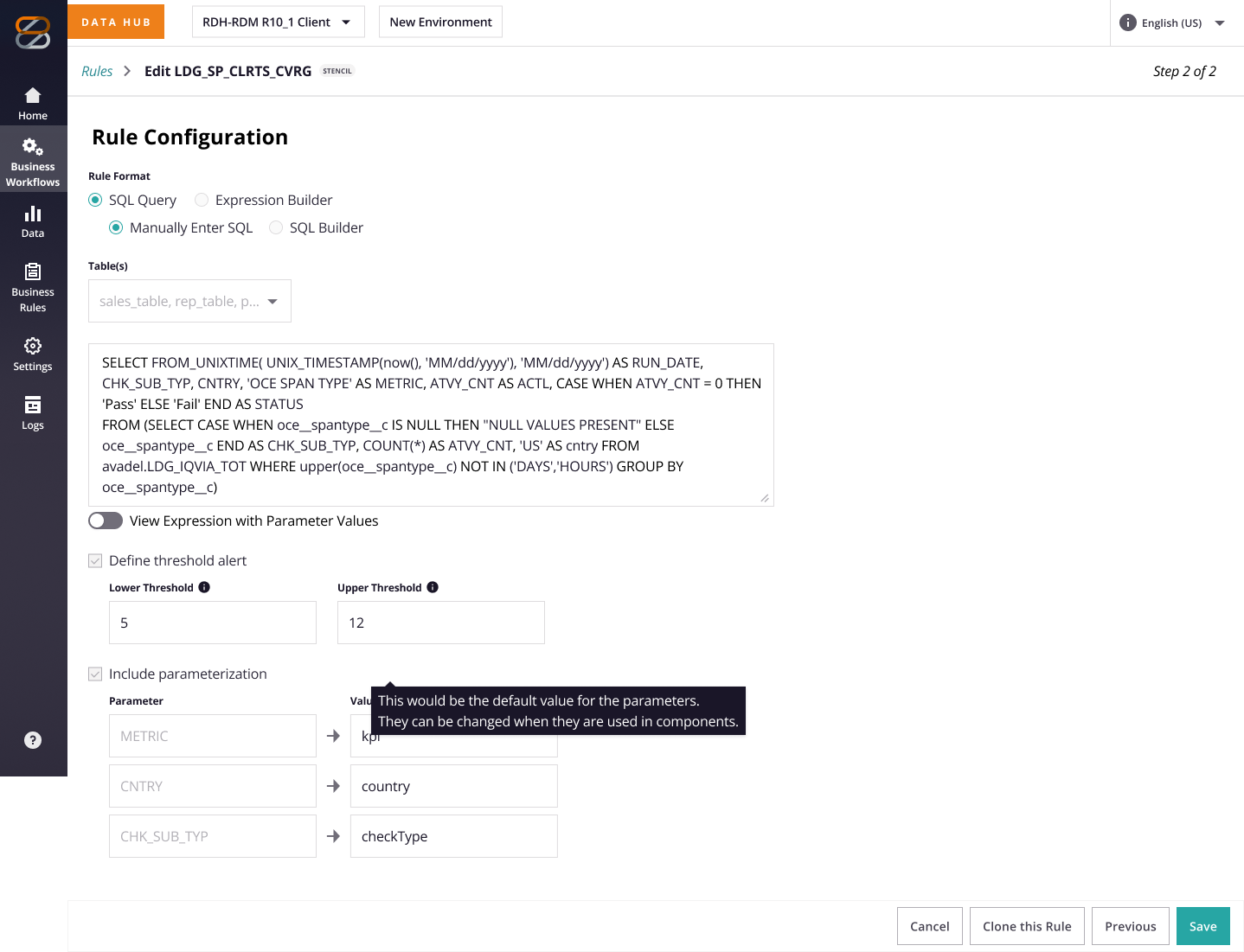
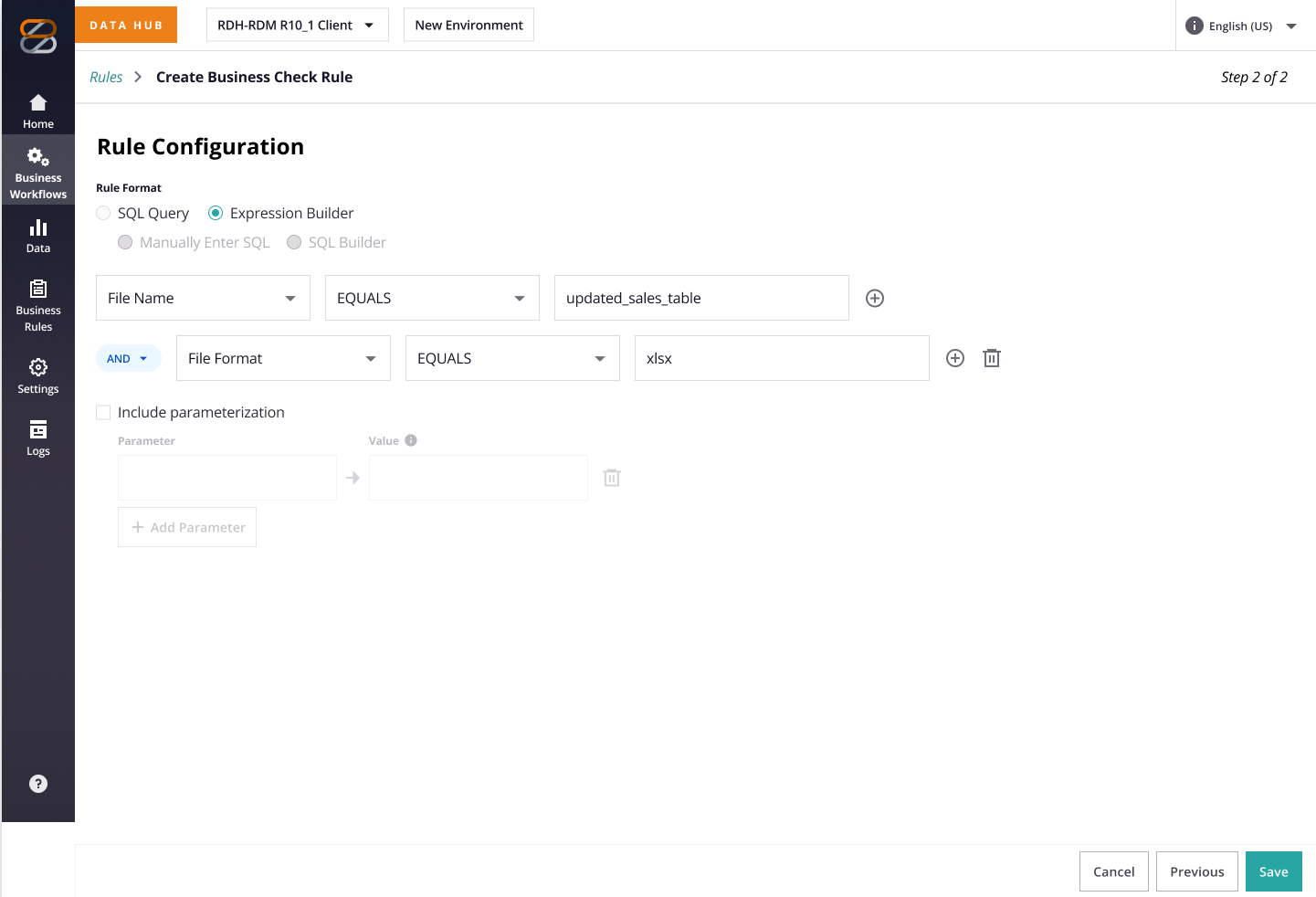
3.3 PPS Buy-in & Conflict Resolution
Cascade reviews with Engineering, QA, and Architecture kept patterns reusable and
developer-friendly.
The toughest audience was the PPS Leadership. Their initial pushback stemmed from two
core tensions:
- Job security concerns: The self-serve shift was perceived as a potential threat to their roles
- Misalignment on feature priorities: they had a backlog of technical needs that didn’t always line up with the PM’s vision for client-facing tooling
As a result, feedback was slow and guarded, with some gatekeeping around access to scripts and process logic.
Why is this being prioritized? We’ve suggested several other items that feel like higher priorities.”
What’s the plan for the SQLs we’ve been maintaining? Migrating everything to this new feature will take a lot of time.”
“This isn’t right. We need to decide whether this check runs before or after filtering. That distinction is important to us.”
I worked closely with the PM to reframe the feature as workload relief: highlighting version control, reusable import libraries, and reduced client confusion. That pivot changed the tone. After two rounds of iteration, including integrating their tasks around sequencing and library import, they signed on and even assigned a dedicated PPS analyst to help us.
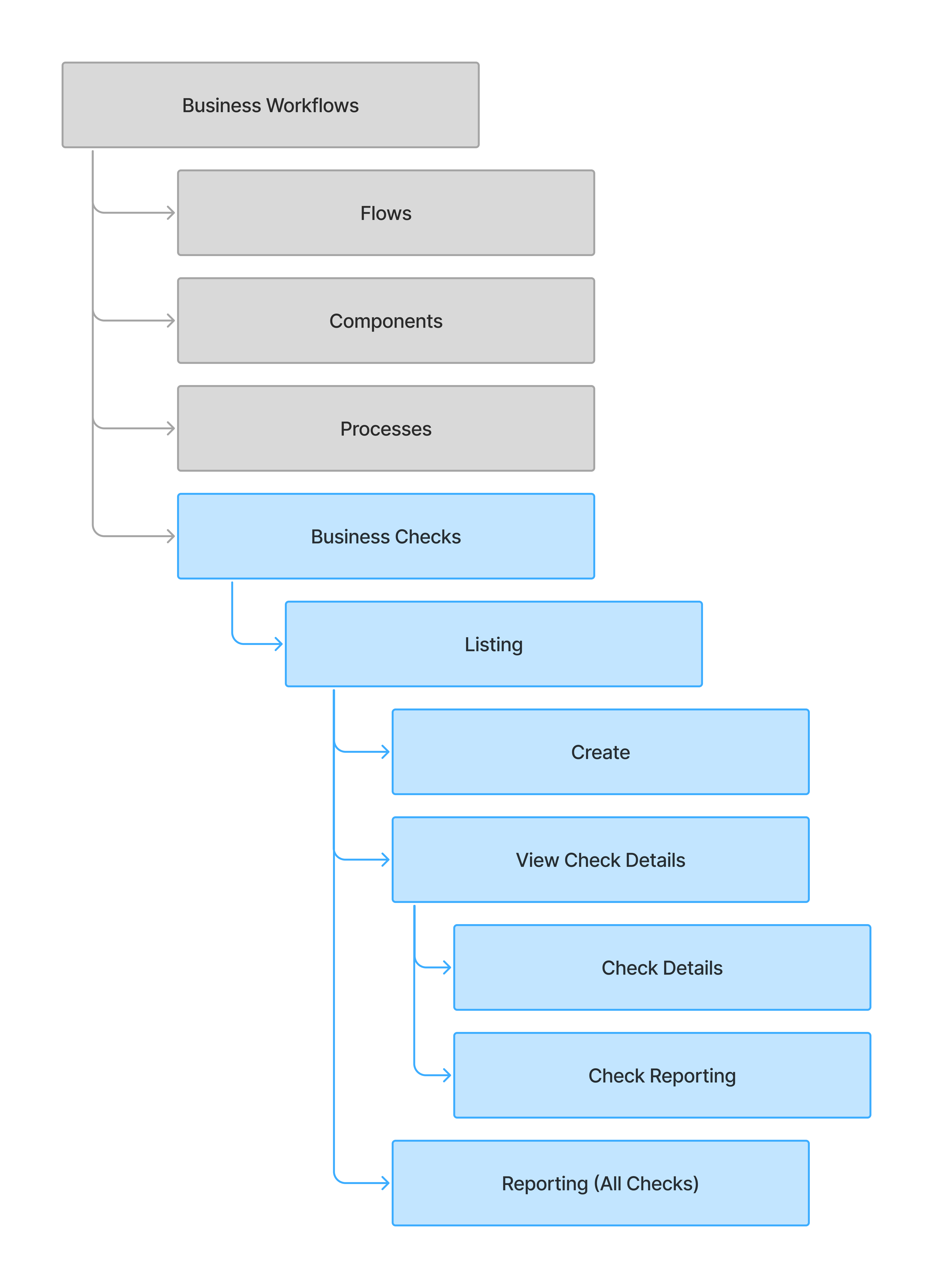
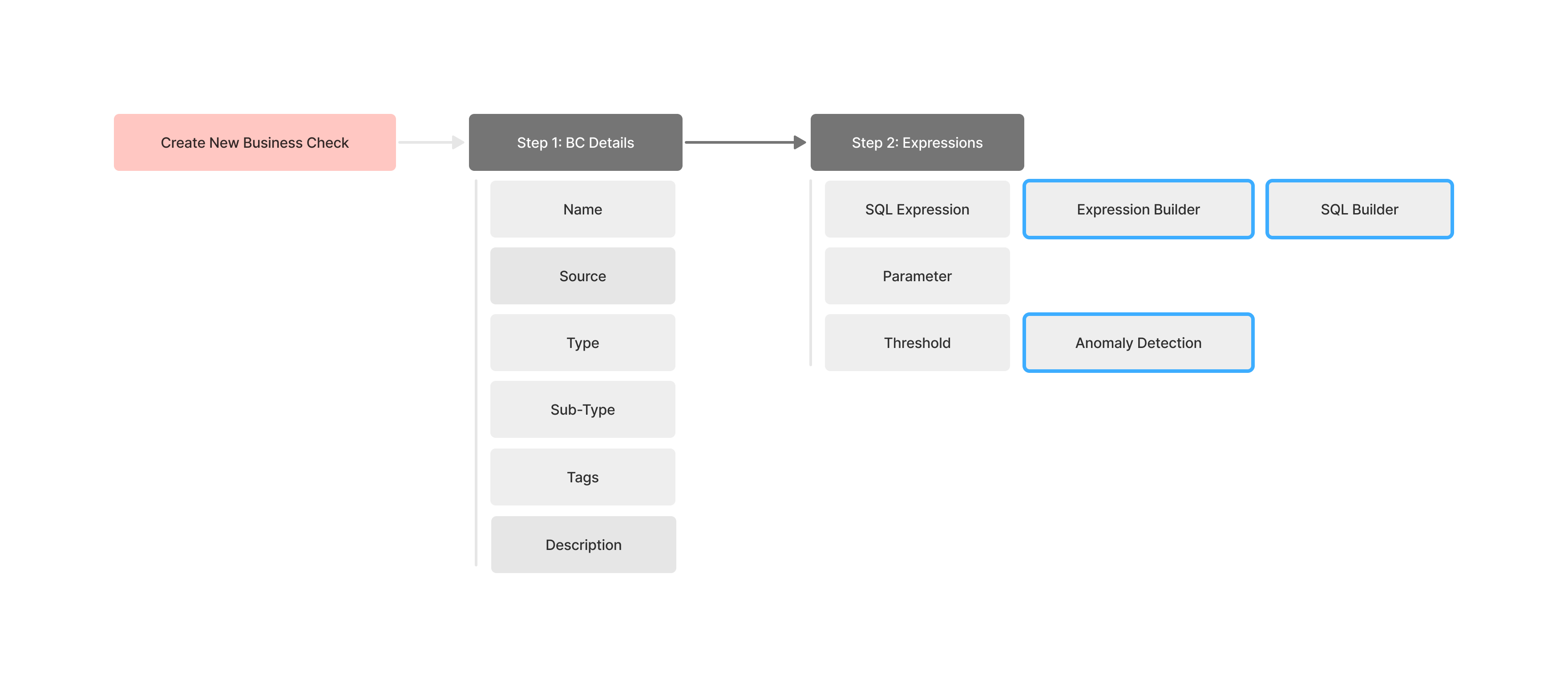
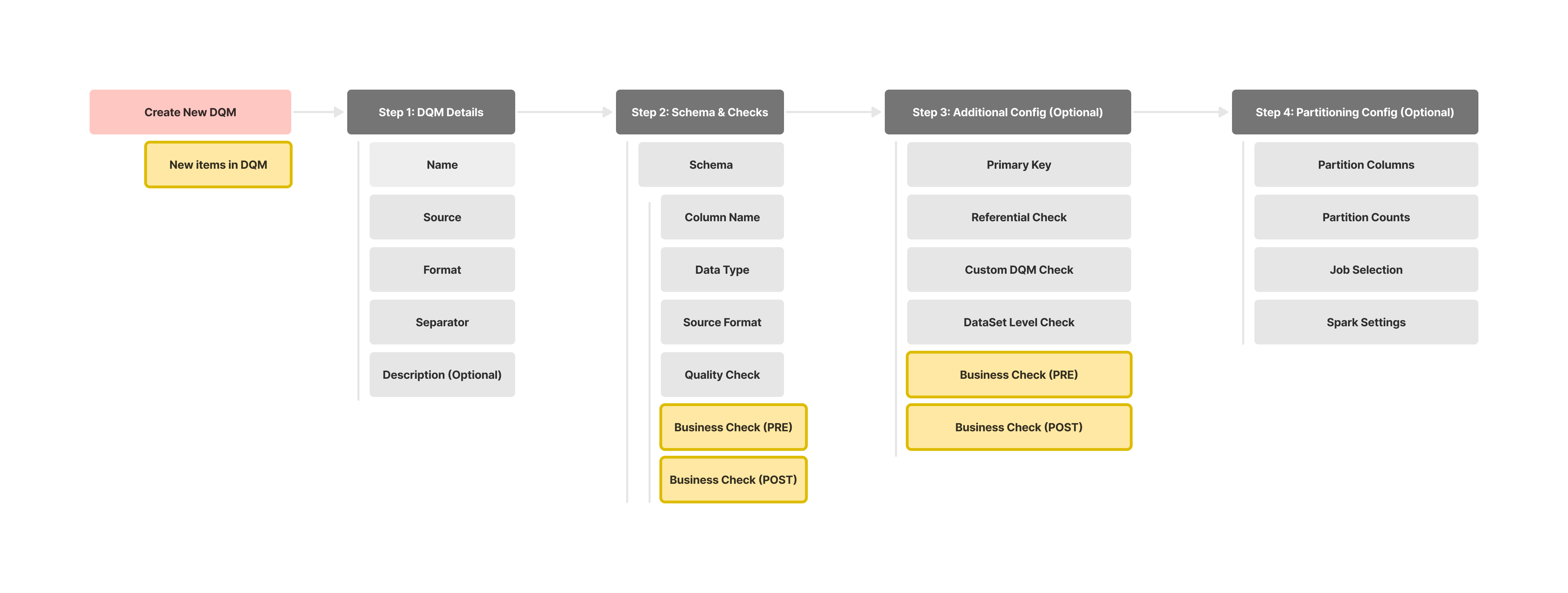
3.4 Scope Decisions: Feature-Cut Matrix
With the PPS feedback, we surfaced a more complete feature set, but not everything could fit into the first iteration. By partnering with the PM and working closely with Engineering to assess effort and trade-offs, we prioritized what to keep, what to defer, and what would deliver the most impact with the least complexity.
| Feature | Impact | Effort | Decision | Why |
|---|---|---|---|---|
| Hybrid builder | High | Medium | MVP | Core to self-serve |
| Sequencing toggle | Medium | Low | MVP | Data accuracy |
| Import library | Medium | Low | MVP | Smooth migration |
| AI anomaly detection | High | High | Later | Need ML Team |
| Multi-level reporting | Med | Medium | Later | Out of the sprint |
4. Outcomes & Wins
The work began as a narrow request: “Can we drop a SQL-builder UI into the product?” However, discovery revealed a larger issue: hundreds of off-platform scripts were causing silent data errors and consuming support resources. I reframed the effort into a Centralized Business Check Repository that would surface, govern, and track every check, transforming a tooling request into a self-serve data-quality initiative.
| Result | Evidence |
|---|---|
| Org alignment | Weekly cross-discipline syncs maintained momentum; all teams signed off on the hybrid spec before the pause. |
| Design package for dev | The design package is ~80% drafted. The remaining specifications are pending and will be finalized upon resumption of development on the 2025 roadmap. |
| Stronger PPS partnership | Built a direct working relationship with PPS analysts and leadership: looped into conversations and reviews alongside PMs for the first time. This helped establish trust and opened the door for faster access to context and feedback going forward. |
| Leadership readiness | Led the end-to-end design process: from framing the problem and aligning cross-functional stakeholders to delivering implementation-ready specs. Drove the initiative forward across teams, built consensus, and secured critical buy-in from both technical and business stakeholders. |
Note:The project is currently paused, but its artifacts remain in the design system, ready for a 2025 restart.
5. Reflection & Next Steps
What worked:
Low-fidelity flowcharts helped align teams early by exposing technical constraints and
clarifying workflows. Building early alliances with PMs, developers, and design peers
provided crucial support for navigating complex decisions.
What I’d change:
Spend more time upfront fostering balanced stakeholder dynamics, especially with expert
teams like PPS, to avoid misalignment and ensure mutual understanding of priorities.
Following launch tasks (when restarted):
- Build a thin AI anomaly-detection feature.
- Layer dashboard reporting atop existing pass/fail data
- Utilize the PPS partnership to establish a consistent POC for continued user-centered validation and cross-functional alignment.